Benchmarks¶
The benchmark results were produced by the scripts in examples/benchmarks, e.g.:
examples/benchmarks/generate_configuration.sh lennard_jones
examples/benchmarks/run_benchmark.sh lennard_jones
The Tesla GPUs had ECC enabled, no overclocking or other tweaking was done.
Simple Lennard-Jones fluid in 3 dimensions¶
Parameters:
- 64,000 particles, number density
- force: lennard_jones (
)
- integrator: verlet (NVE,
)
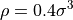
| Hardware | time per MD step and particle | steps per second | FP precision | compilation details |
|---|---|---|---|---|
| Intel Xeon E5-2640 | 1.44 µs | 10.8 | double | GCC 4.7.2, -O3 |
| NVIDIA Tesla S1070 | 57.0 ns | 274 | double-single | CUDA 5.5, -arch compute_12 |
| 55.1 ns | 284 | single | CUDA 5.5, -arch compute_12 | |
| NVIDIA Tesla C2050 | 39.4 ns | 397 | double-single | CUDA 5.5, -arch compute_12 |
| 34.3 ns | 456 | single | CUDA 5.5, -arch compute_12 | |
| NVIDIA Tesla K20m | 22.2 ns | 702 | double-single | CUDA 5.5, -arch compute_12 |
| 20.7 ns | 756 | single | CUDA 5.5, -arch compute_12 | |
| NVIDIA Tesla K20Xm | 19.7 ns | 792 | double-single | CUDA 5.5, -arch compute_12 |
| 18.4 ns | 851 | single | CUDA 5.5, -arch compute_12 |
Results were obtained from 1 independent measurement based on pre-release
version 1.0-alpha1. Each run consisted of NVT equilibration at 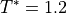 over
over  (10⁴ steps), followed by benchmarking 10⁴ NVE 5
times steps in a row.
(10⁴ steps), followed by benchmarking 10⁴ NVE 5
times steps in a row.
Supercooled binary mixture (Kob-Andersen)¶
Parameters:
256,000 particles, number density
force: lennard_jones with 2 particle species (80%
, 20%
)
(
,
,
,
,
,
,
,
)
integrator: verlet (NVE,
)
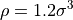
| Hardware | time per MD step and particle | steps per second | FP precision | compilation details |
|---|---|---|---|---|
| Intel Xeon E5-2640 | 2.03 µs | 1.93 | double | GCC 4.7.2, -O3 |
| NVIDIA Tesla S1070 | 65.7 ns | 59.4 | double-single | CUDA 5.5, -arch compute_12 |
| 66.3 ns | 58.9 | single | CUDA 5.5, -arch compute_12 | |
| NVIDIA Tesla C2050 | 39.2 ns | 99.7 | double-single | CUDA 5.5, -arch compute_12 |
| 32.4 ns | 120 | single | CUDA 5.5, -arch compute_12 | |
| NVIDIA Tesla K20m | 18.5 ns | 211 | double-single | CUDA 5.5, -arch compute_12 |
| 17.0 ns | 230 | single | CUDA 5.5, -arch compute_12 | |
| NVIDIA Tesla K20Xm | 16.2 ns | 242 | double-single | CUDA 5.5, -arch compute_12 |
| 15.0 ns | 261 | single | CUDA 5.5, -arch compute_12 |
Results were obtained from 1 independent measurement and are based on
pre-release version 1.0-alpha1. Each run consisted of NVT equilibration at
 over (2×10⁴ steps), followed by
benchmarking 10⁴ NVE steps 5 times in a row.
over (2×10⁴ steps), followed by
benchmarking 10⁴ NVE steps 5 times in a row.